论文题目
Uninformed Students: Student-Teacher Anomaly Detection with Discriminative Latent Embeddings
该文是发表在CVPR 2020的文章,文章主要通过ensemble的学生和pretrained的老师来进行无监督的异常检测。该文的新意不但在于用师生网络进行异常检测,还使用了判别式嵌入而非重建的方法,并且实现了精确到像素级的分割。
Motivations
1.目前无监督异常分割较为依赖于生成模型
目前无监督异常分割的主流方法依赖于生成方法居多,像GAN以及AE重建的思想。基于这种思想,异常检测是通过逐像素去重建或是根据数据概率分布的估计去重建,重建像素如果比较复杂有可能会导致错误的重建。
2.目前无监督领域判别式嵌入的方法有待挖掘
在迁移学习中,从预训练模型得到的判别式嵌入提高了有监督领域迁移的性能。作者发现在无监督领域使用判别式嵌入的方法泛化性能比深度生成模型要好。
3.判别式的有些方法有时会过度依赖于下采样
对于复杂的高维数据集,使用判别式嵌入的方法需要降维,因为判别式方法是属于浅层方法,它们建模特征空间的容量不足以支撑庞大数据的复杂分布。
Contributions
1.在无监督异常检测领域使用师生框架
文章在无监督异常检测领域结合见过正负样本的预训练的老师和只见过正样本的学生,利用判别式嵌入的思想来做异常检测。
2.融合了集成学习的思想
对于集成的学生,是利用老师与学生之间预测的差异以及学生与学生之间的差异来获得异常图。
3.分割方法新颖
分割方法新颖,分割异常采用的是输入不同大小的图像块进行多尺度的方法。
做法
整体框架
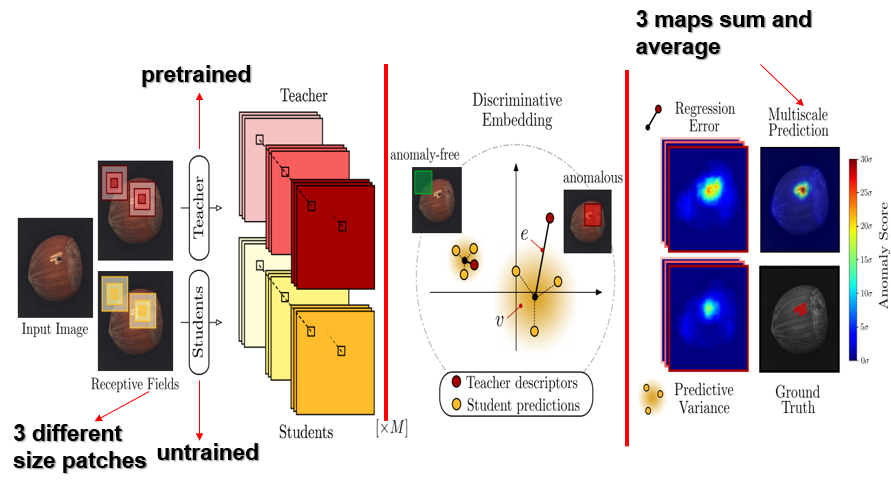
本文提出的判别式嵌入的师生框架,可分为三个部分,第一部分是经过预训练的教师网络和M个随机初始化产生的ensemble的学生网络,其中教师网络有利用到正常数据和异常数据的图像块去pretrain,第二部分是两个网络对于同一输入的判别式描述,第三部分是多尺度分割模块组成。整个框架训练是采用的是正常的数据集的图像块。训练时是通过教师网络的输出的embedding(注意看上图中红色Teacher descriptors)去教导学生如何embed正常的样本(注意看上图中黄色Student predictions),学生网络是通过回归误差和预测的方差去学习的。最后通过3个异常图的加权平均分割出异常。
教师网络使用正常和异常的数据来预训练,学生网络只使用正常的数据来训练。采用上述训练方法有两个的好处。
(1)在测试时遇到异常样本时,由于教师没有教导学生什么是异常样本,但教师知道什么是异常样本,所以学生网络输出会和教师网络输出差异较大;
(2)在测试时遇到异常样本时,由于几个ensemble的学生都没见过异常样本,所以在学生之间输出会比较不一致。
教师网络的训练
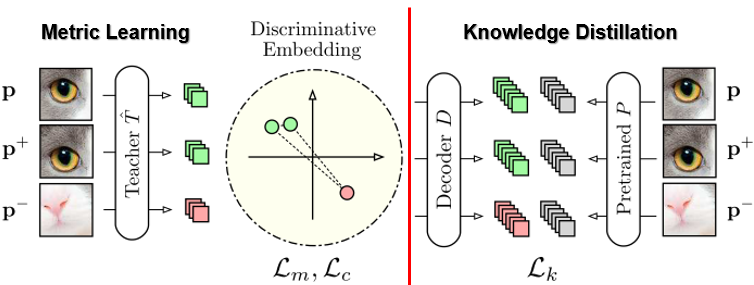
教师网络的训练主要分为度量学习和知识蒸馏两部分。这里度量学习是学习到三个距离$\delta$,$\delta^+$,$\delta^-$来完成对正负样本的差异性的判断。给定三元组($p,p^+,p^-$),判别式嵌入要做的事情是让$p$和$p^+$的距离最小,$p$和$p^+$距离$p^-$的距离尽量大。公式如下。
$$ \delta^+ = \vert\vert \hat T(p)-\hat T(p^+)\vert\vert^2 $$
$$ \delta^- = min\lbrace\vert\vert \hat T(p)-\hat T(p^-)\vert\vert^2 ,\vert\vert \hat T(p^+)-\hat T(p^-)\vert\vert^2\rbrace $$
度量学习的loss为
$$ L_m(\hat T)=max\lbrace0,\delta+\delta^+-\delta^-\rbrace $$
通过度量学习得到学习正负样本的差异性。对于右边的知识蒸馏模块,它是用一个已经可以分类正负样本的Resnet-18网络$P$对判别式的输出embedding用蒸馏的方法得到网络$\hat T$。知识蒸馏这块的loss为
$$ L_k(\hat T)=\vert\vert D(\hat T(p))-P(p)\vert\vert^2 $$
为了去除输入图像块之间的冗余信息,用$c_{ij}$来表示输入图像块$P$之间的协方差矩阵,得到去冗余度的loss如下。
$$ L_c(\hat T)=\sum_{i\neq j}c_{ij} $$
学生网络的训练
在文中,对于文中每一张图像块,学生网络输出假设是服从高斯分布的,它的训练主要依赖于学生与老师之间的回归误差以及学生与学生之间的预测不确定度,回归误差指的是M个学生$S_i$在第$r$行和第$c$列上的点预测的均值减去老师描述的二范数的平方。
预测的不确定度是指M个学生$S_i$在第$r$行和第$c$列上预测点的均值$\mu_{(r,c)}^{S_i}$的二范数的平方求平均减去预测点的均值$\mu_{(r,c)}^{S_i}$求平均的二范数的平方。总的loss是回归误差和预测不确定度的归一化操作。

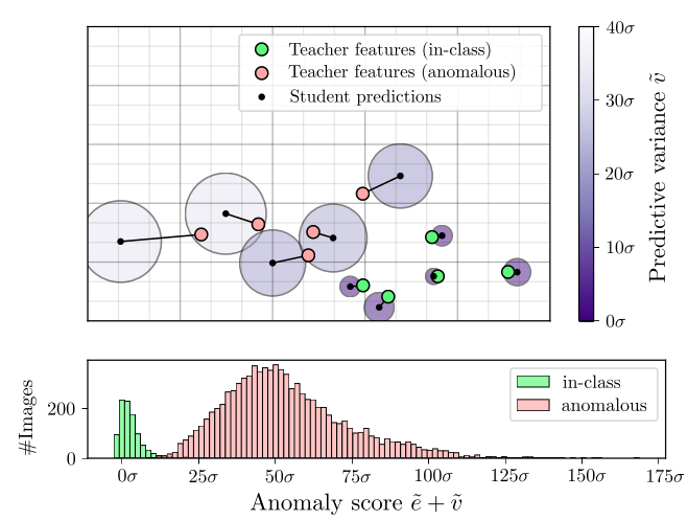
举例子来说,在MNIST数据集上,用0作为正常样本,其他数字为异常样本,可以得到如下关于正常样本和异常样本的正态的数据分布图。教师网络是用0-9所有的数据去训练的,学生网络只用正常样本去回归和预测,很明显教师知道什么是正常和什么是异常,学生只知道正常的。所以学生预测出的结果如上所示,对于正常的样本,学生回归误差和预测的方差都偏小,对于异常样本,回归误差和预测方差都偏大。
多尺度分割
利用输入多个不同大小的图像块得到的学生网络回归误差和预测的不确定度的异常map进行加权平均,可得到如下结果。
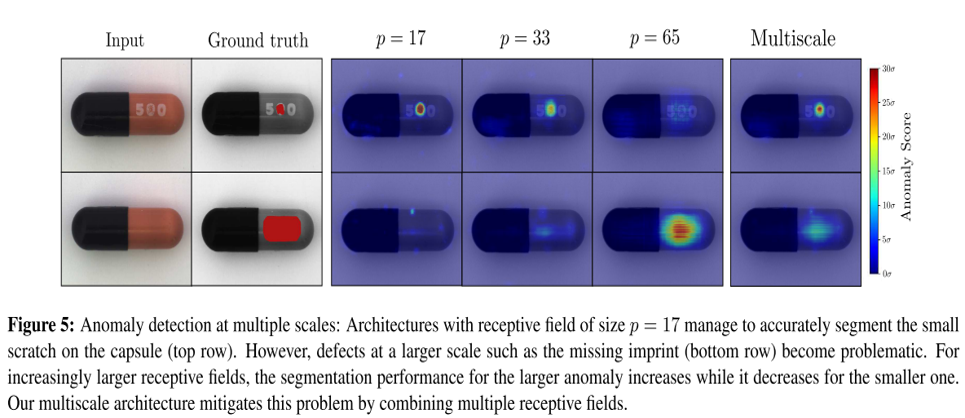
可得多尺度分割结论:对于不同异常的分割,分割性能的大小与P的size有关,P太大,小块的异常会被当成正常,P太小,大块的异常被当作正常。
缺点
1.多尺度的方法过于粗糙,文章中仅仅是使用三个异常map的加权平均,其实可以改为更多的map;
2.分割性能的大小与输入图像块的size有关,size太大,小块的异常会被当成正常,size太小,大块的异常被当作正常,不知道能不能让输入图像块的大小在某个范围内具有自适应性调整。
数据集
1.MVTec Anormal Detection Dataset: https://www.mvtec.com/company/research/datasets/mvtec-ad
2.MNIST: http://yann.lecun.com/exdb/mnist/
3.CIFAR-10: https://www.cs.toronto.edu/~kriz/cifar.html


